Browser steps when you type a URL

In this article, I gonna explain and structure the fundamental steps the browser does starting from that moment when a user types the url to the final step when browser shows the page. You can also look at a very-detailed post which I also used for structuring this article.
Short steps are:
- You enter a URL into a web browser
- The browser parses the URL (is it URL or search-term)
- The browser looks up the IP address for the domain name via DNS
- The browser establishes a connection to the server
- The browser sends a HTTP request to the server
- The server sends back a HTTP response
- The browser begins rendering the HTML
- The browser sends requests for additional objects embedded in HTML (images, css, JavaScript) and repeats steps 5-7.
- Once the page is loaded, the browser sends further async requests as needed.
Let's get into details:
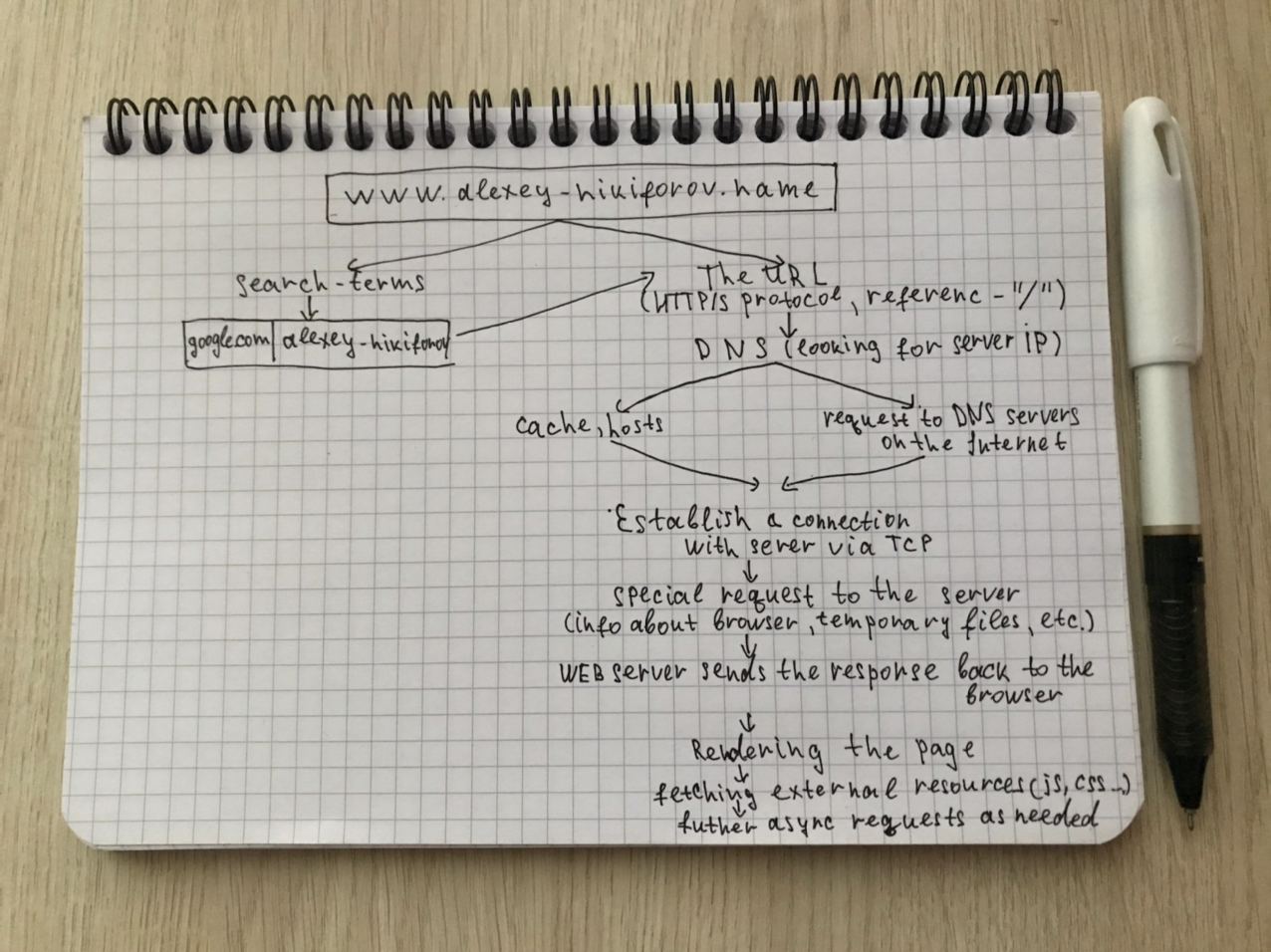
- You typed for example - 'www.alexey-nikiforov.name' URL and press the enter button.
-
If it's a
search-termsthe browser passes the text in the address box to the browser's default web search engine. If it's URL then the browser will keep the following information:- Protocol
HTTPSorHTTPS - Resource
/
- Protocol
- The first thing browser needs to understand what the IP address of the server on which the site is located. This information is keeping in DNS (Domain Name System). In order to speed up work the browser checks if the domain is in the
cacheor in the localhostsfile and takes the information from here.
If not found it generates a request to DNS servers located on the Internet. - Once the browser has learned the IP address it tries to establish a connection with him. In most cases it uses the TCP protocol.
TCP (Transmission Control Protocol)is a standard that defines how to establish and maintain a network conversation through which application programs can exchange data. TCP works with the Internet Protocol (IP), which defines how computers send packets of data to each other. - After establishing a connection, the browser sends a special request to the server in which it asks to send the data for display a page. This request contains info about the browser, temporary files and etc.
The browser's functionality is to present the web resource (html, image, pdf, javascript, css, etc.) you choose, by requesting it from the server and displaying it in the browser window. - When the response is complete, the web server sends it back to the browser. The response usually contains content for display webpage, cookies, data compression type information end etc.
- The rendering engine starts getting the contents of the requested document from the networking layer. This will usually be done in 8kB chunks.
The primary job of HTML parser is to parse the HTML markup into a parse tree.
The output tree (the "parse tree") is a tree of DOM element and attribute nodes. DOM is short for Document Object Model. It is the object presentation of the HTML document and the interface of HTML elements to the outside world like JavaScript. The root of the tree is the "Document" object. Prior of any manipulation via scripting, the DOM has an almost one-to-one relation to the markup. - The browser begins fetching external resources linked to the page (CSS, images, JavaScript files, etc.).
- Then the browser sends further async requests as needed. For example in SPA (single page application) applications when you change the page you need to get new data without refreshing the page.